一部理想的宇宙漫游作品,不仅是美感与想象的结合,更是对天文数据的独特解读。我们坚信,每个选题都蕴含着无限潜力,承载了大家对宇宙的向往,而数据就是通往那片无垠之海的钥匙。如何告别天文数据可视化的新手阶段,迈向更深远的星空?下面就继续跟随“玩转数据,轻松漫游”系列专题,继续解锁数据的神奇密码。
最近推出的宇宙漫游作品征集活动成功吸引了我的注意,于是我也跃跃欲试琢磨起了自己的作品。选题迟迟没头绪,不如从数据中找找灵感。如果你也是数据处理的新手,希望通过数据讲述引人入胜的故事,那咱们就一起学着用可视化技术来探索数据的魅力吧。
1. 数据获取
1.1 数据来源
在准备阶段,我看到之前的专题文章推荐了很多科学数据平台,从中选择了郭守敬望远镜观测数据开始“新手试炼”。
进入国家天文科学数据中心官网之后,选择导航栏的“科学数据”的选项,再点击下拉菜单的“数据检索”按钮,即可跳转到数据集下载目录,最后选择LAMOST的观测数据。
.PNG)
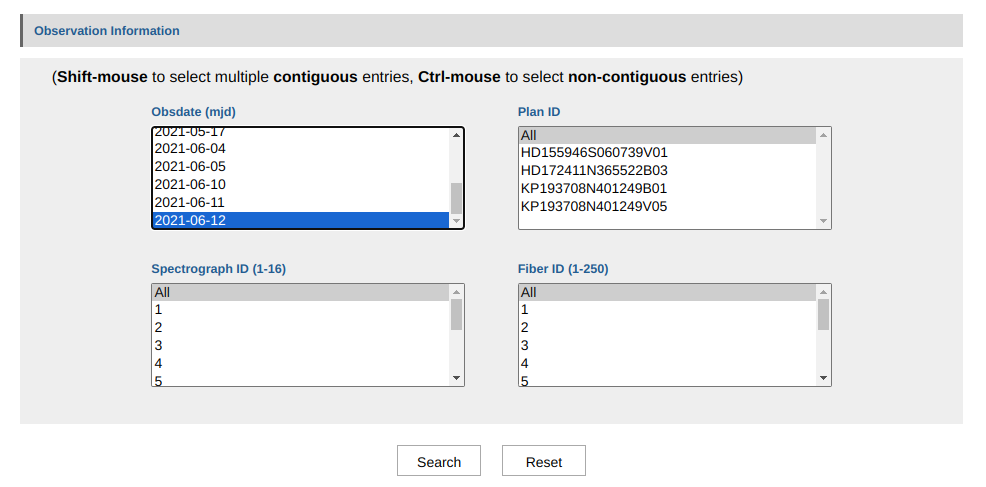
进入数据库后,可以进一步选择数据集的释放版本,我选择了DR9 v2.0的低分辨率数据,并在“Observation Information”分类下,下载了2021-06-12的所有观测数据。
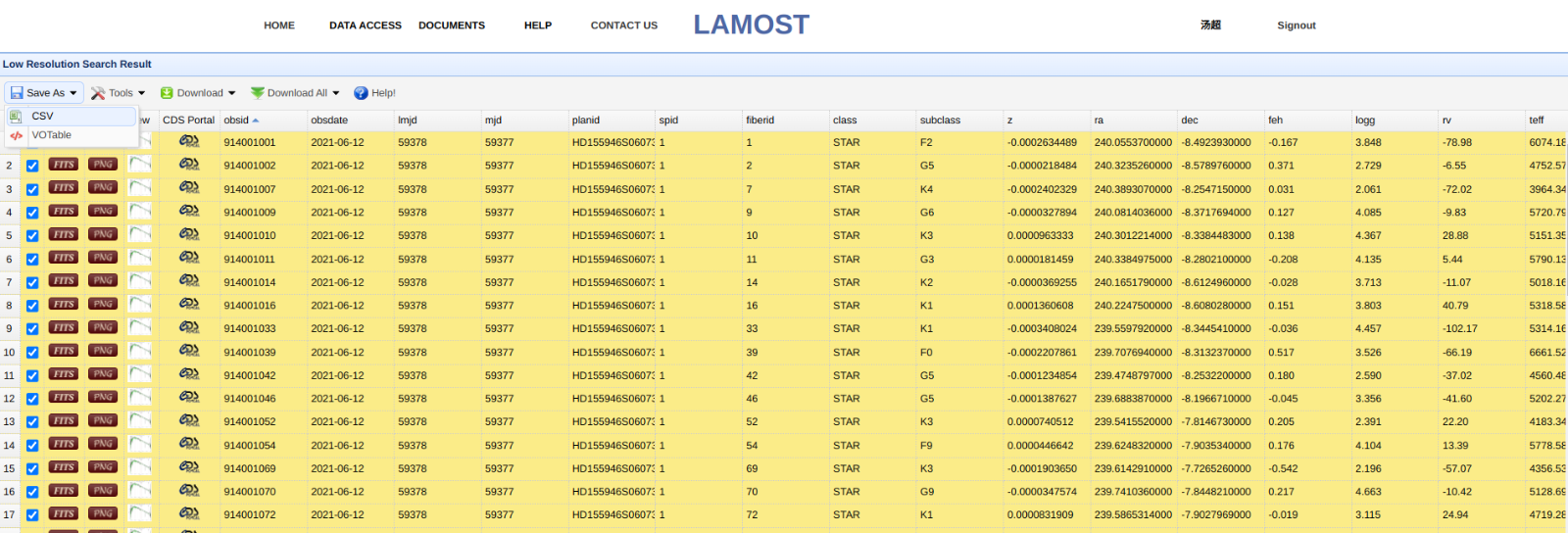
接着点击“Search”按钮,跳转至数据详情页面,在左上角菜单栏中选择“Save As—CSV”即可完成数据集的下载。
1.2 数据清洗
获取到原始数据后,需要进行一定的预处理,进行数据清洗可以:
- 确保数据质量:原始数据可能包含重复、缺失、异常值或不一致的信息。通过数据清洗,可以检测并修复这些问题,提高数据的准确性和完整性。
- 确保一致性:数据清洗有助于确保数据的一致性,使得相同类型的数据具有相同的格式、单位和范围,便于进行比较和分析。
- 提高数据可视化效果:清洗数据可以改善数据可视化的效果。干净的数据能够更好地支持图表和图形的生成,使得数据更易于理解和传达。
数据清洗技术种类很多,因为我平时对Python编程语言和pandas库很熟悉,于是决定选择使用这种方法操作。
# 导入pandas库
import pandas as pd
# 加载csv文件数据,注意将文件目录替换为自己的(相对/绝对路径皆可)
file_name = './data/30515.csv'
data =pd.read_csv (file_name)
# 这里看一下CSV数据的整体情况 -》结果(行数,列数)
print(data.shape)
输出结果如下图所示:
.PNG)
咦?奇怪!为什么只有一列数据呢,我们将表头打印出来再检查一下。
print(data.shape)
# 结果为:
['combined_obsid|combined_obsdate|combined_lmjd|combined_mjd|combined_planid|combined_spid|combined_fiberid|combined_class|combined_subclass|combined_z|combined_ra|combined_dec|combined_feh|combined_logg|combined_rv|combined_teff']
原来是数据被“压缩”成一列了。但是通过观察又发现,原本的列索引元素被“|”符号隔开了,看来只需要重新组织一下CSV文件就可以了。
# 导入csv库
import csv
# 设置文件路径
file_name = './data/30515.csv'
new_file_name='./data/30515-modified.csv'
# 读取原始的文件数据
row_csv_data= []
with open(file_name, 'r') as csv_file:
csv_reader=csv.reader(csv_file)
forrowincsv_reader:
# 将每行数据按照“|”符号区分开
row_csv_data.append(row[0].split('|'))
withopen(new_file_name, 'w') as csv_file:
csv_writer = csv.writer(csv_file)
# 将处理后的数据写入新文件
csv_writer.writerows(row_csv_data)
最终得到的结果如下图所示,大家可以对比一下校正前后的数据表格:

校正之前的数据表格
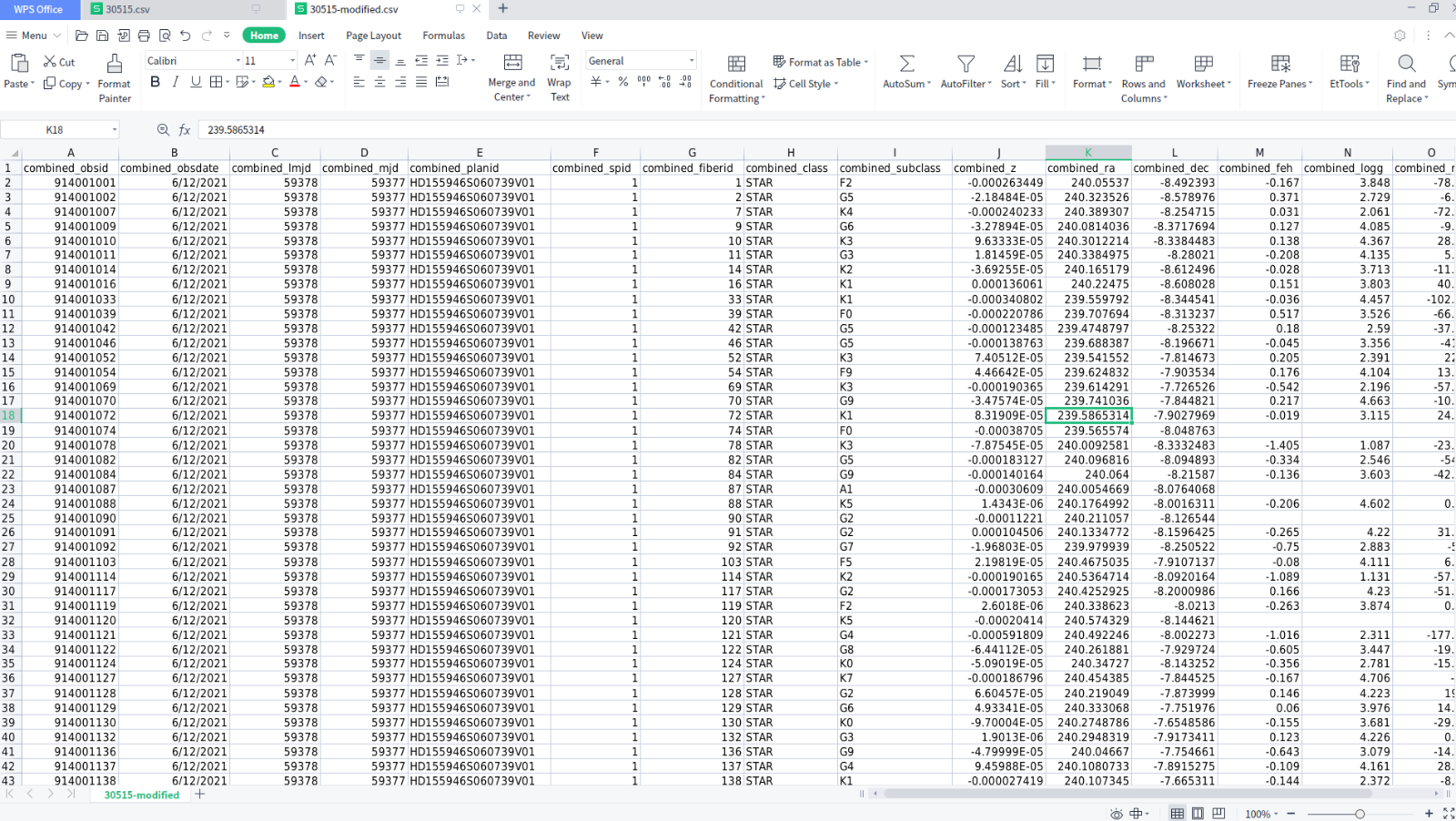
校正之后的数据表格
接下来,我继续从宏观上查看CSV文件数据校正后的数据结构,操作如下:
data = pd.read_csv(new_file_name)
print(data.shape)
从结果来看,我选择的数据集共有6803行16列。输入下面的命令,还可以查看更多的细节信息。
print(data.info())
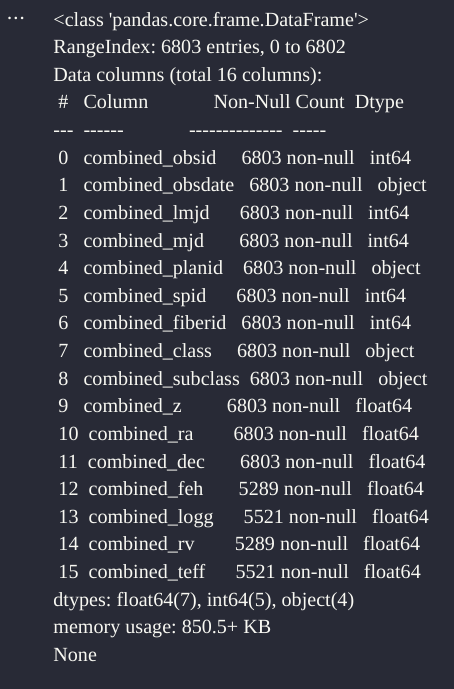
从输出的DataFrame信息中,首先我们可以从中获得数据的总体信息,比如它的行数、列数等。其次,列信息显示出了数据的更多细节,例如它的 combined_obsid(观测ID)、combined_obsdate(观测日期)、combined_lmjd(Local Modified Julian Data)、combined_mjd(Modified Julian Date)等的记录数。此外,还可以从中了解数据的特点,比如我看到一些列存在缺失值等,例如 `combined_feh`、`combined_logg`、`combined_rv` 和 `combined_teff`。大家还可以参考LAMOST DR9的发布文档,进一步了解这些数据对应的信息。
显然,原始数据中存在一小部分的缺失值。由于我们暂时无法补全,为了方便后面的可视化,在这里选择直接将含有缺失值的行删除。
data_delete_none =data.dropna()
print(data_delete_none.info())
事实上,数据清洗是一项复杂而关键的任务,涉及到检测和纠正数据集中的错误、缺失、异常值等问题:
例如,我们想检查数据中是否有重复,可以用下面的方法打印重复结果。
# 返回重复的行数
print(data_delete_none.duplicated().sum())
我下载的数据中并没有重复的(返回值为0),很好!
但如果有重复行,可以这样删除:
# 删除重复值,修改源数据
data_delete_none.drop_duplicates(inplace=True)
# 重建索引
data_cleaned =data_delete_none.reset_index(drop=True)
print(data_cleaned.info())
数据清洗还可以实现数据标准化,将不同尺度和范围的数据转换为相同的标准,以确保模型训练的稳定性和可靠性。这是一个迭代的过程,通常需要反复检查和调整。处理完成后,将数据保存到指定路径下的文件就可以了。
data_cleaned_file_name ='./data/30515_cleaned.csv'
data_cleaned.to_csv(data_cleaned_file_name)
2. 数据可视化
完成数据清洗之后,就进入数据可视化步骤了。我尝试着使用了三种不同的工具来操作,大家也可以根据需要选择不同的工具进行数据展示哦!
2.1 Matplotlib
先是Matplotlib,它是最常见最广泛使用的Python绘图库,让我先来看一下这批数据中包含的天体类别和各类别占比。
# 导入matplotlib库
import matplotlib.pyplot as plt
# combined_class
data = pd.read_csv(data_cleaned_file_name)
# 统计每个唯一值的频率
value_counts =data['combined_class'].value_counts()
# 绘制饼图
plt.figure(figsize=(8, 8))
plt.pie(value_counts, labels=value_counts.index, autopct='%1.1f%%', startangle=90)
# 显示饼图
plt.show()
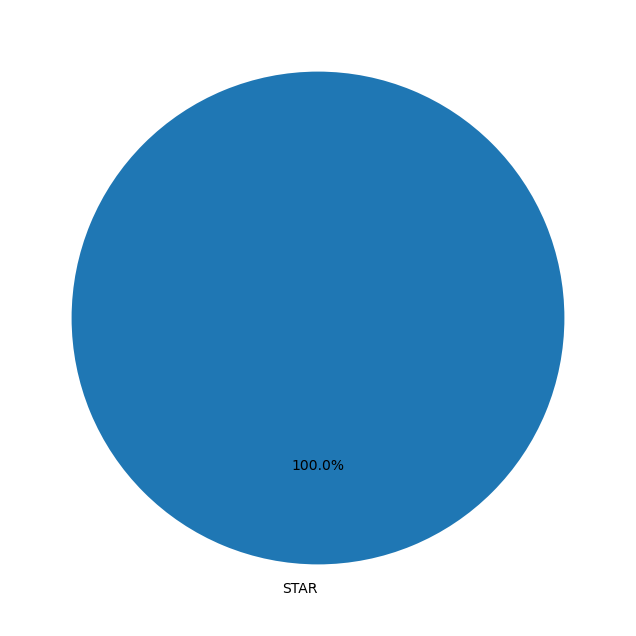
生成后,我发现所有的数据都是恒星(STAR)类型。原来21年6月12日所有的观测数据都是这一类型,没有星系和类星体。那么它们都是什么类型的恒星呢?可以进一步根据子类别进行可视化。
# 统计每个唯一值的频率(combined_subclass)
value_counts =data['combined_subclass'].value_counts()
# 绘制饼图
plt.figure(figsize=(8, 8))
plt.pie(value_counts, labels=value_counts.index, autopct='%1.1f%%', startangle=90)
# 显示饼图
plt.show()
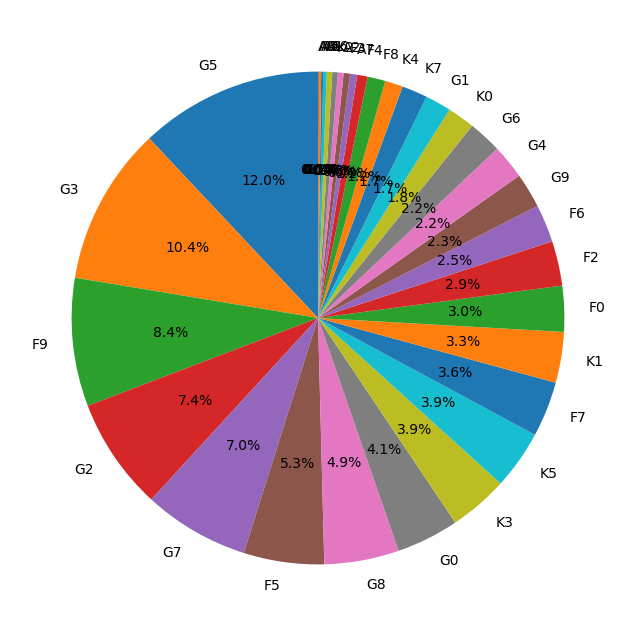
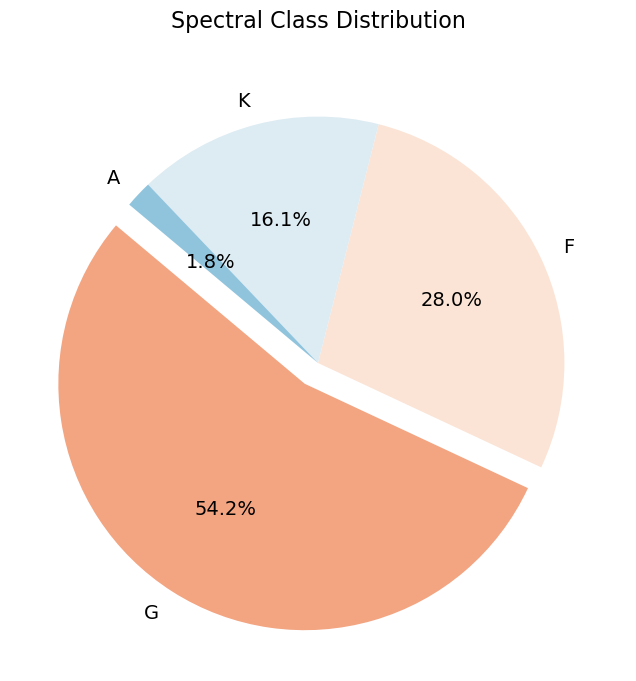
再次生成后的饼图果然显示出了数据的更多特点!图上显示的是基于恒星表面温度和光谱特征分类的光谱类型。光谱类型一般由一个字母和一个数字组成,温度从高到低常用的类别有O、B、A、F、G、K、M等,紧随字母的数字用来提供更细的温度分类,范围从0到9。
问题又来了,现在的展示方式不太美观,而且因为类别过多,缺乏标题、图例等图表元素,看上去很乱又无法找到特点。我决定尝试把恒星光谱进行合并归类,如下:
# 添加新分类
data['spectral_class'] =data['combined_subclass'].str[0]
# 保存修改后的DataFrame到新的CSV文件
modified_file_path ='cleaned_with_spectral_class.csv'
data.to_csv(modified_file_path, index=False)
importnumpyas np
value_counts=data['spectral_class'].value_counts()
plt.figure(figsize=(10, 8))
plt.pie(value_counts, labels=value_counts.index, autopct='%1.1f%%', startangle=140, explode=[0.1 if v ==value_counts.max() else 0.0 for v in value_counts], colors=plt.cm.RdBu(np.linspace(0.3, 0.7, len(value_counts))), textprops={'fontsize': 14})
plt.title('Spectral Class Distribution', pad=20, fontsize=16)
# 显示饼图
plt.show()
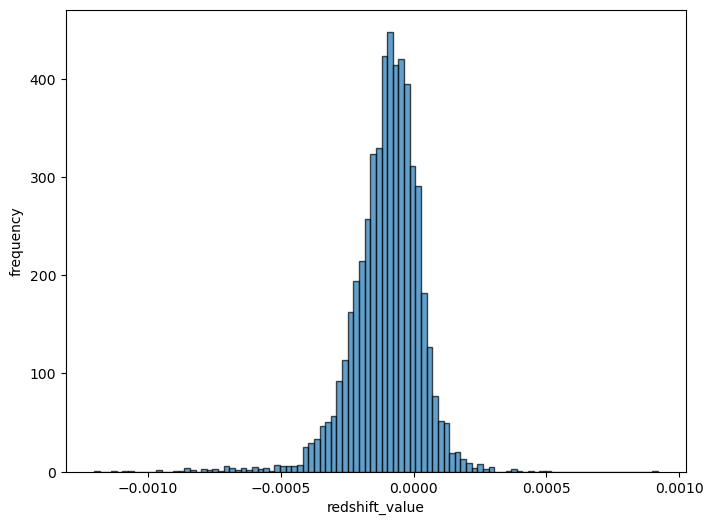
为了了解这批观测数据的更多信息,我们还可以可视化它的其他,比如红移分布等。
# 绘制直方图
plt.figure(figsize=(8, 6))
plt.hist(data['combined_z'], bins=100, edgecolor='black', alpha=0.7)
# 设置坐标系
plt.xlabel('redshift_value')
plt.ylabel('frequency')
# 显示直方图
plt.show()